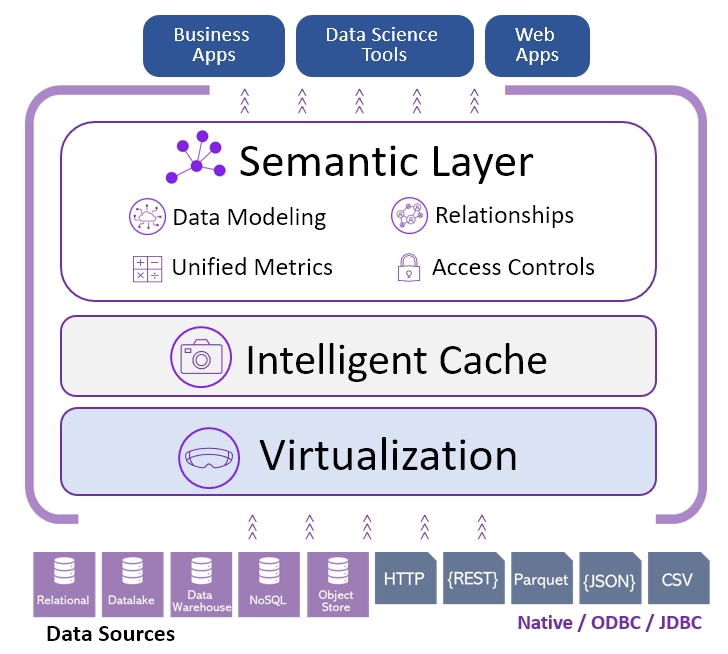
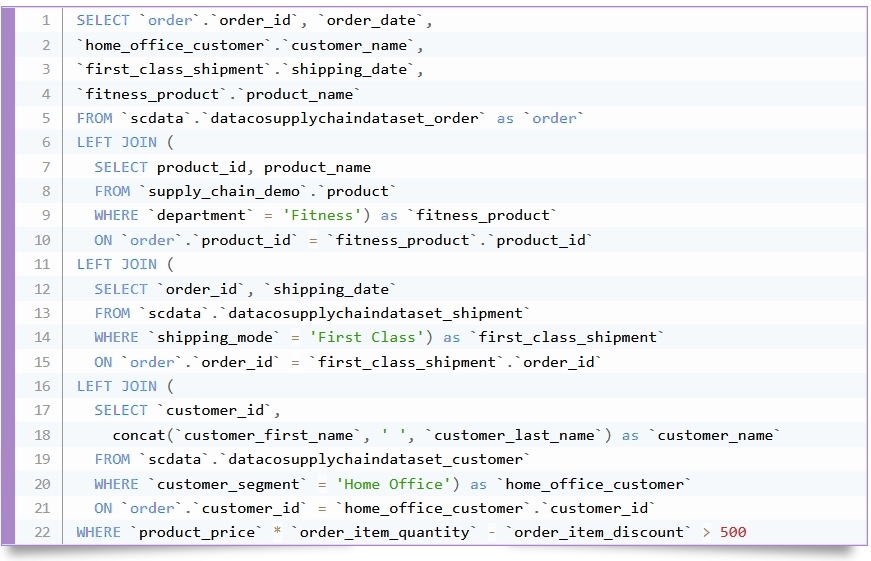
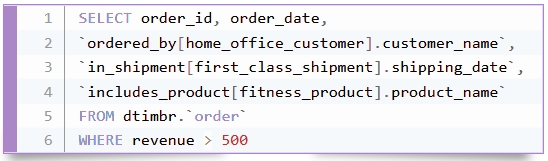
Model and integrate data with business meaning and relationships, unify metrics and accelerate delivery of data products with 90% shorter SQL queries and semantic REST API
Play Video
“Timbr is the most powerful, yet simple to implement semantic platform for the SQL ecosystem”
Industry leaders use Timbr to connect data in a meaningful way:
Industry leaders use Timbr to connect data in a meaningful way:
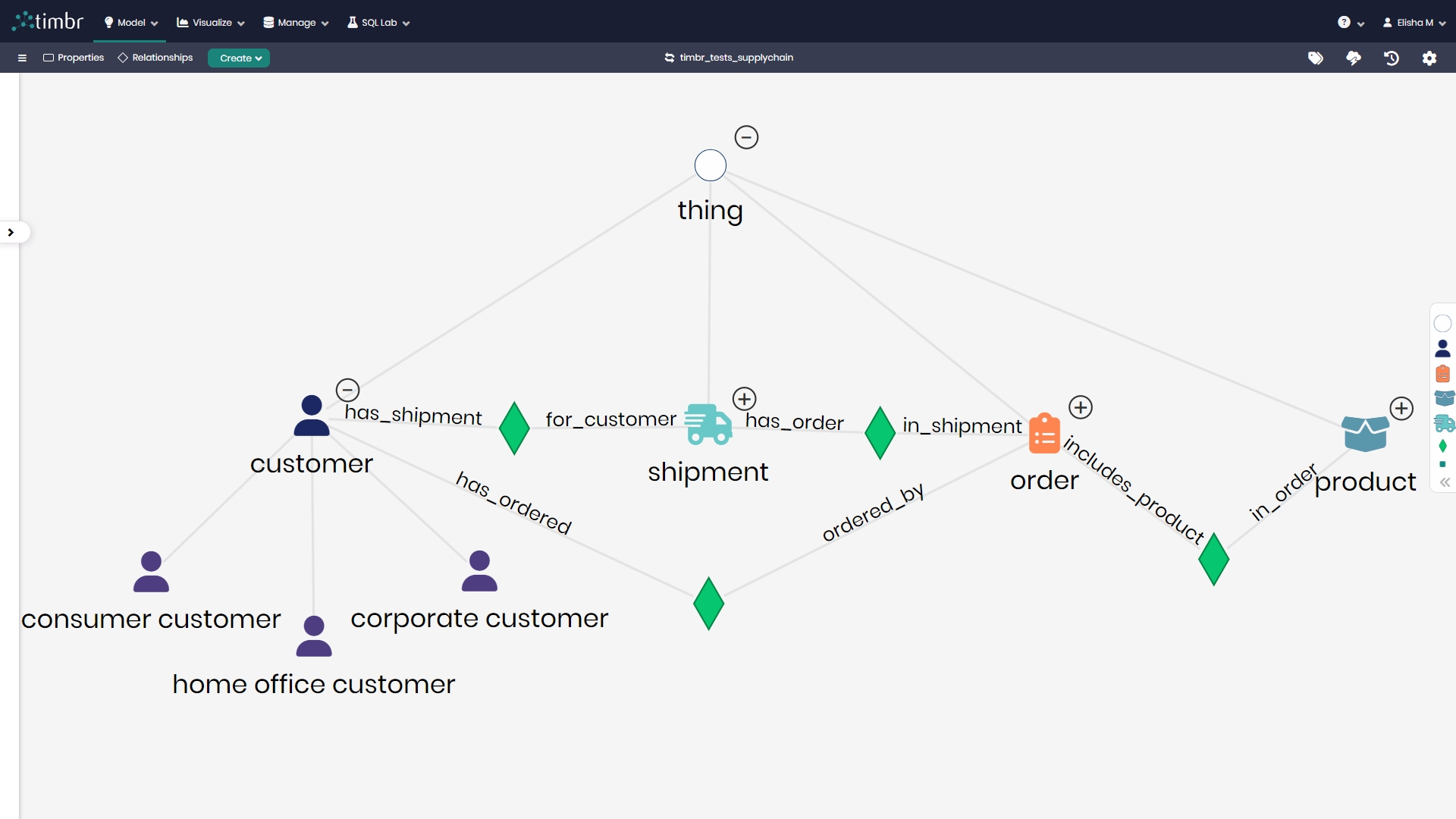
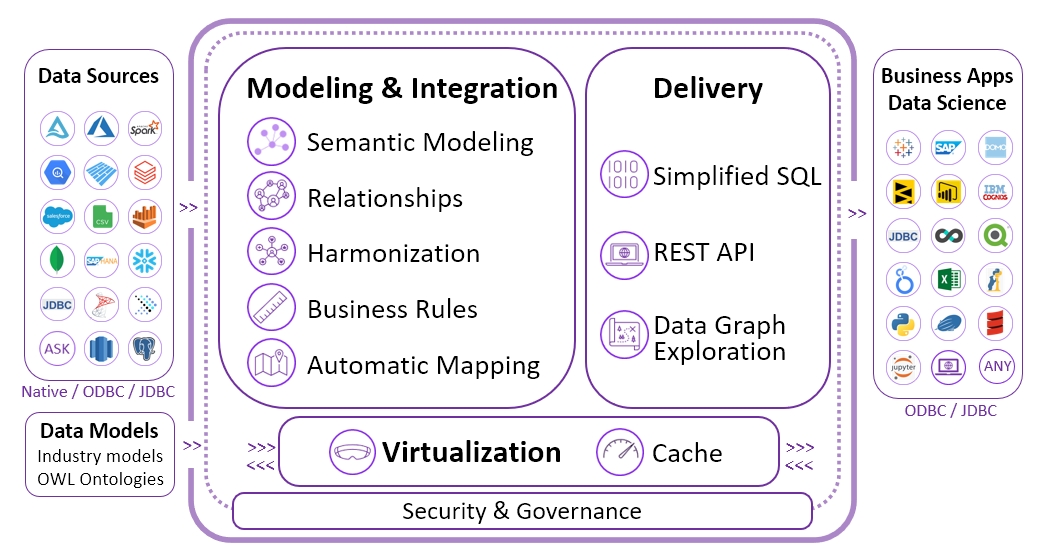
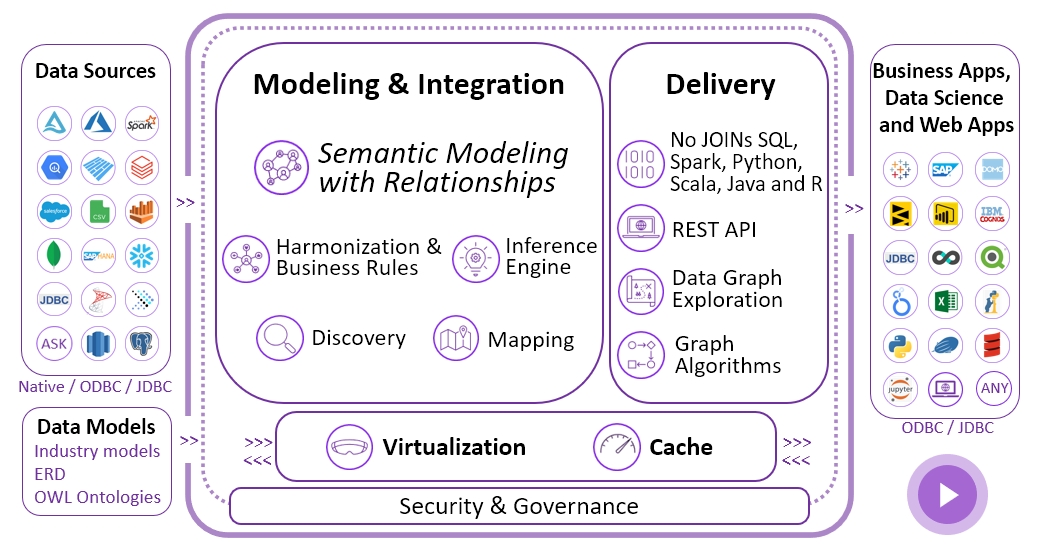
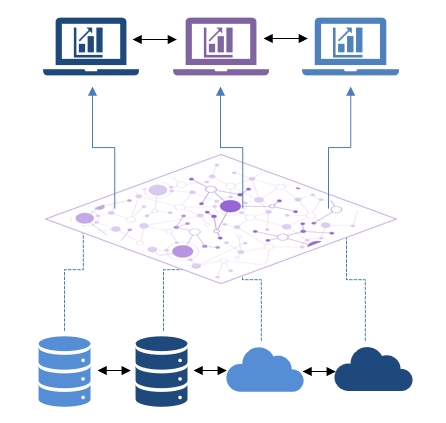
Connect to most clouds, datalakes, data warehouses, databases and any file format. Timbr empowers you to work with your data sources seamlessly.
How you store your data is up to you. By default, nothing is stored in Timbr. When a query is run, Timbr optimizes the query and pushes it down to the backend.
1 GARTNER Cool Vendors in Data Management, June 01, 2021. ID: G00746797. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. The GARTNER COOL VENDOR badge and GARTNER are registered trademarks and services marks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
1 GARTNER Cool Vendors in Data Management, June 01, 2021. ID: G00746797. Analysts: Philip Russom , Ehtisham Zaidi , Jason Medd , Eric Thoo , Robert Thanaraj. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. The GARTNER COOL VENDOR badge and GARTNER are registered trademarks and services marks of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Start typing and press enter to search
We use cookies on our website to give you the most relevant experience by remembering your preferences and repeat visits. By clicking “Accept”, you consent to the use of ALL the cookies.
This website uses cookies to improve your experience while you navigate through the website. Out of these cookies, the cookies that are categorized as necessary are stored on your browser as they are essential for the working of basic functionalities of the website. We also use third-party cookies that help us analyze and understand how you use this website. These cookies will be stored in your browser only with your consent. You also have the option to opt-out of these cookies. But opting out of some of these cookies may have an effect on your browsing experience.
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.
Thank You!
Our team has received your inquiry and will follow up with you shortly.
In the meantime, we invite you to watch demo and presentation videos of Timbr in our Youtube channel: